R中的循环,除了手动for循环(不推荐)、apply函数家族,还有purrr包中的map()函数家族。
purrr包中的map()函数是函数的函数,这样的编程方式成为泛函式编程,表示函数作用在函数上。
map()函数通过循环迭代可以确定返回的数据类型,如下:
- map_chr(.x, .f): 返回字符型向量
- map_lgl(.x, .f): 返回逻辑型向量
- map_dbl(.x, .f): 返回实数型向量
- map_int(.x, .f): 返回整数型向量
- map_df(.x, .f) : 返回数据框
- map_dfr(.x, .f): 返回数据框列表,再 bind_rows 按行合并为一个数据框
- map_dfc(.x, .f): 返回数据框列表,再 bind_cols 按列合并为一个数据框
1. map()
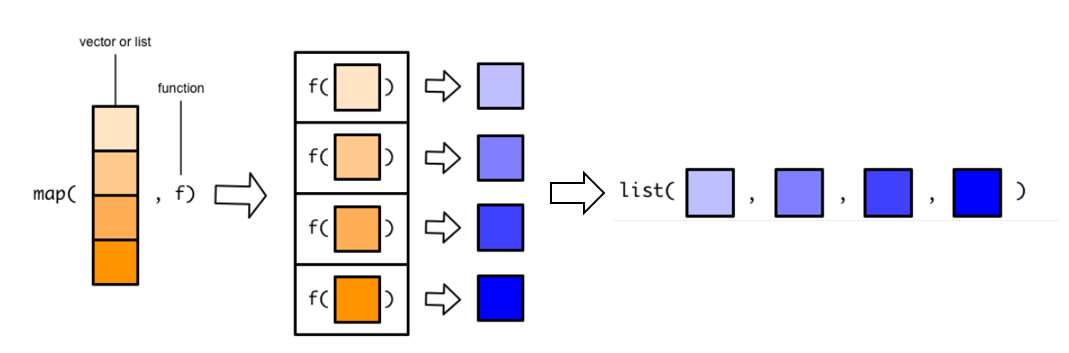
map(x,f)函数第一个参数是list或vector,第二个参数是函数,map()将函数f应用到list/vector的每个元素,然后输入的list/vector中的每一个元素都对应一个输出,最后将这些元素对应的输出聚合成一个新的list。
data.frame是列表的一种特殊形式,所以数据框也可以作为map函数的输入。
过程如下图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| data <- list(
col1 = round(runif(10, 50, 100)),
col2 = round(runif(10, 50, 100)),
col3 = round(runif(10, 50, 100)),
col4 = round(runif(10, 50, 100)),
col5 = round(runif(10, 50, 100))
)
data
$col1
[1] 80 74 90 75 64 70 51 84 67 68
$col2
[1] 97 82 97 100 62 85 74 99 66 67
$col3
[1] 69 82 91 51 94 87 86 77 57 53
$col4
[1] 88 62 59 92 61 96 94 69 65 64
$col5
[1] 79 92 50 57 92 94 61 59 70 68
|
用map函数求每个col的均值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| map(data,mean)
data %>% map(mean)
$col1
[1] 72.3
$col2
[1] 82.9
$col3
[1] 74.7
$col4
[1] 75
$col5
[1] 72.2
|
等价于:
1
2
3
4
5
6
7
| list(
col1 = mean(exams$col1),
col2 = mean(exams$col2),
col3 = mean(exams$col3),
col4 = mean(exams$col4),
col5 = mean(exams$col5)
)
|
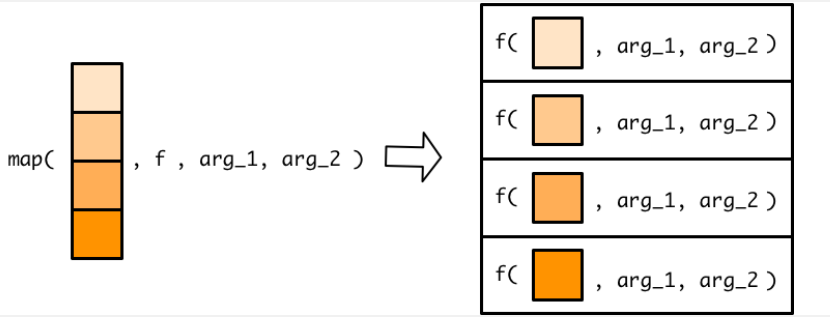
map函数也可以添加其他f的参数:
过程如图:
例如,降序排列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| data %>% map(sort, decreasing=TRUE)
$col1
[1] 90 84 80 75 74 70 68 67 64 51
$col2
[1] 100 99 97 97 85 82 74 67 66 62
$col3
[1] 94 91 87 86 82 77 69 57 53 51
$col4
[1] 96 94 92 88 69 65 64 62 61 59
$col5
[1] 94 92 92 79 70 68 61 59 57 50
|
2. map()函数家族
2.1 map_dbl()
如果每个元素是数值型,map_dbl()会聚合所有元素构成一个原子型向量:
返回数值型向量:
1
2
3
| data %>% map_dbl(mean)
col1 col2 col3 col4 col5
72.3 82.9 74.7 75.0 72.2
|
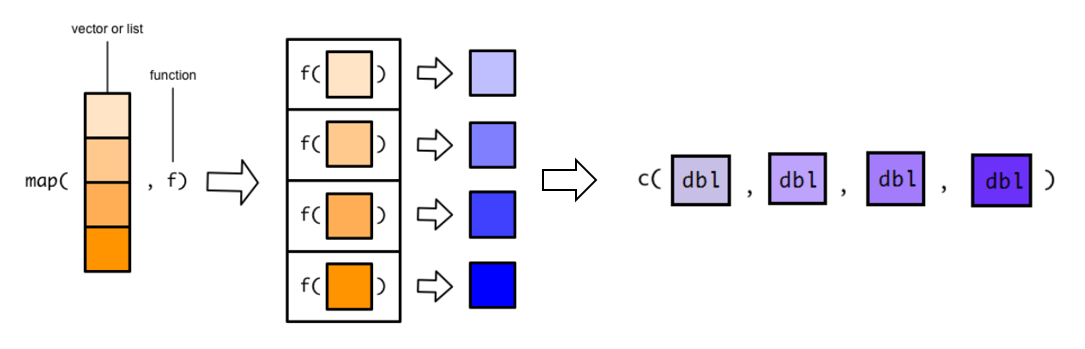
2.2 map_df()
返回数据框:
1
2
3
4
5
| data %>% map_df(mean)
col1 col2 col3 col4 col5
<dbl> <dbl> <dbl> <dbl> <dbl>
1 72.3 82.9 74.7 75 72.2
|
其他类似的函数也是一样的用法。
2.3 map_at()
根据一个位置向量,在指定位置进行某个函数操作:
1
2
3
| data %>% map_at(c(1,3),sqrt)
data %>% map_at(c("col1","col3"),sqrt)
|
2.4 map_if()
1
2
3
4
5
6
7
|
```R
is_even <- function(x){
!as.logical(x %% 2)
}
data$col3 %>% map_if(is_even, sqrt)
|
2.5 map_df()、map_dfr()、map_dfc()
map_df()过程:
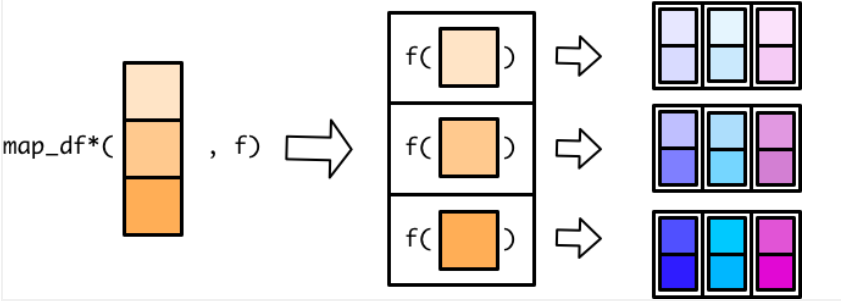
map_dfr()过程:
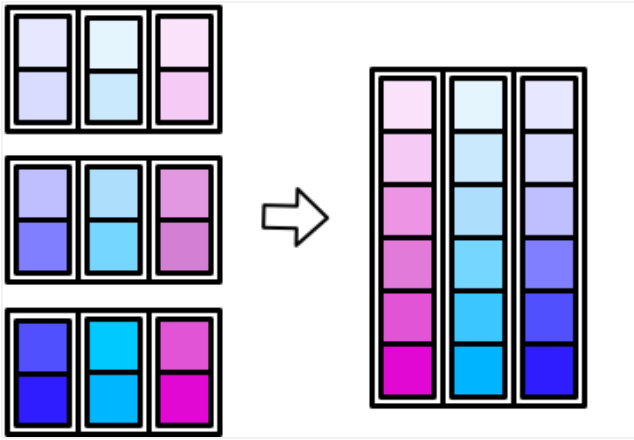
map_dfc()过程:
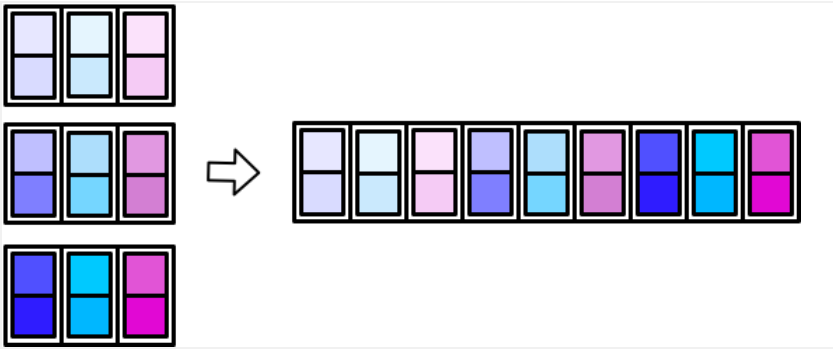
3. 自定义函数
1
2
3
4
5
6
7
8
9
| my_fun <- function(x){
mean(x) + sd(x)
}
data %>% map_df(my_fun)
col1 col2 col3 col4 col5
<dbl> <dbl> <dbl> <dbl> <dbl>
1 83.3 97.8 90.9 90.4 88.4
|
也可以这样:
1
2
3
4
5
| data %>% map_df(function(x) mean(x)+sd(x))
col1 col2 col3 col4 col5
<dbl> <dbl> <dbl> <dbl> <dbl>
1 83.3 97.8 90.9 90.4 88.4
|
还可以省略function:
1
| data %>% map(~ mean(.x) + sd(.x))
|
甚至可以:
1
| data %>% map(~ mean(.) + sd(.))
|
4. map()和modify()
两者的区别在于map()函数返回的永远是list,但是modify()返回的和输入的对象类型是一样的。modify()函数也有类似于map()函数的其他函数,如modify_if()、modify_at()。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| data %>% map(~ mean(.) + sd(.))
$col1
[1] 83.32573
$col2
[1] 97.84025
$col3
[1] 90.87302
$col4
[1] 90.41284
$col5
[1] 88.36443
data %>% modify(~ mean(.) + sd(.))
$col1
[1] 83.32573
$col2
[1] 97.84025
$col3
[1] 90.87302
$col4
[1] 90.41284
$col5
[1] 88.36443
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| data %>% as_tibble() %>% map(~ mean(.) + sd(.))
data %>% as_tibble() %>% modify(~ mean(.) + sd(.))
col1 col2 col3 col4 col5
<dbl> <dbl> <dbl> <dbl> <dbl>
1 83.3 97.8 90.9 90.4 88.4
2 83.3 97.8 90.9 90.4 88.4
3 83.3 97.8 90.9 90.4 88.4
4 83.3 97.8 90.9 90.4 88.4
5 83.3 97.8 90.9 90.4 88.4
6 83.3 97.8 90.9 90.4 88.4
7 83.3 97.8 90.9 90.4 88.4
8 83.3 97.8 90.9 90.4 88.4
9 83.3 97.8 90.9 90.4 88.4
10 83.3 97.8 90.9 90.4 88.4
|
5. map2()
map2()和map()函数类似,map2()接受两个向量,且向量必须等长。
map2()函数中两个向量的元素,用.x和.y代替。
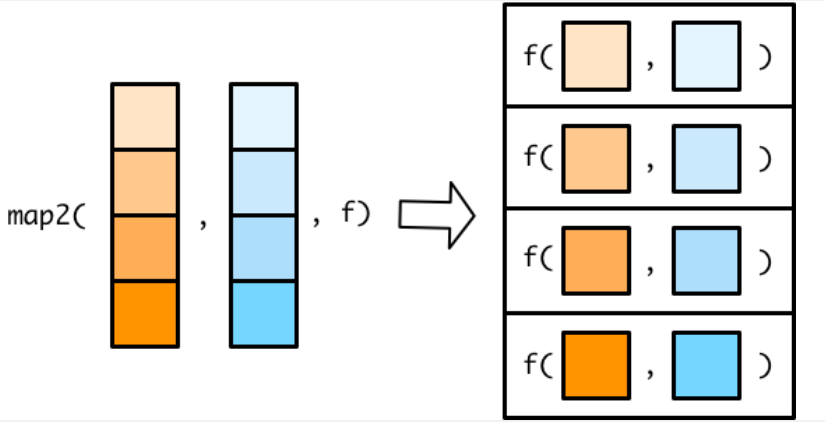
1
2
3
4
5
6
7
8
9
10
11
12
| x <- c(1, 2, 3)
y <- c(4, 5, 6)
map2(x, y, ~ .x + .y)
[[1]]
[1] 5
[[2]]
[1] 7
[[3]]
[1] 9
|
对tibble中不同的列进行迭代:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| df <-
tibble(
a = c(1, 2, 3),
b = c(4, 5, 6)
)
df %>%
mutate(min = map2_dbl(a, b, ~min(.x, .y)))
a b min
<dbl> <dbl> <dbl>
1 1 4 1
2 2 5 2
3 3 6 3
|
6. pmap()
pmap()函数不一样的地方:
- map()函数和map2()函数,指定传递给函数f的向量,向量各自放在各自的位置上
- pmap()需要将函数传递给函数的向量名先装入一个list,然后再传递给函数f
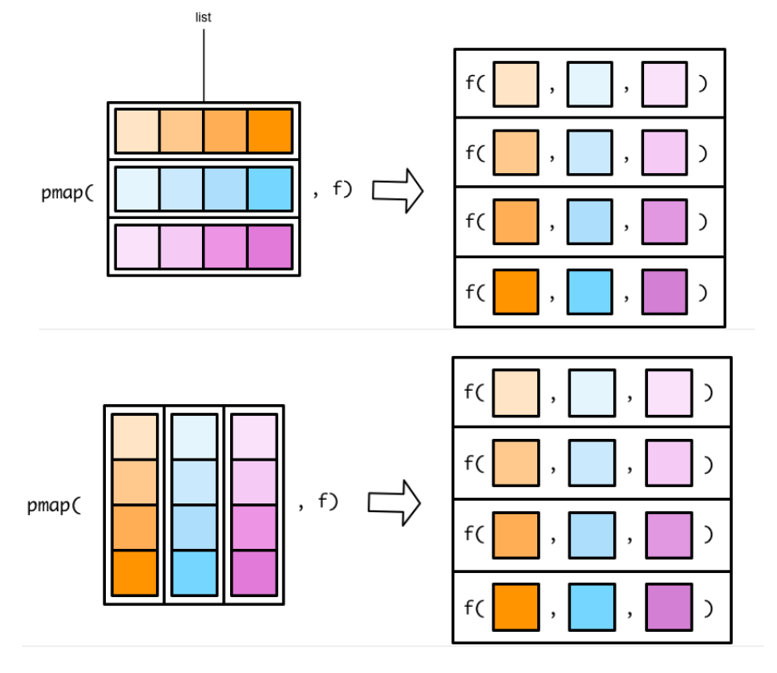
tbible是特殊的list,这种结构可以直接应用函数:
1
2
3
4
5
6
| tibble(
a = c(50, 60, 70),
b = c(10, 90, 40),
c = c(1, 105, 200)
) %>%
pmap_dbl(min)
|
pmap()函数中,用..1、..2、..3分别代表三个向量。
1
2
3
4
5
6
7
8
9
10
11
12
13
| x <- c(1, 2, 3)
y <- c(4, 5, 6)
z <- c(2, 3, 4)
pmap(list(x, y, z), ~ ..1 + ..2 + ..3)
[[1]]
[1] 7
[[2]]
[1] 10
[[3]]
[1] 13
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| params <- tibble::tribble(
~ n, ~ min, ~ max,
1L, 0, 1,
2L, 10, 100,
3L, 100, 1000
)
pmap(params, ~runif(n = ..1, min = ..2, max = ..3))
[[1]]
[1] 0.3534275
[[2]]
[1] 72.76199 92.31143
[[3]]
[1] 207.7082 692.6508 867.5282
|
如果提供给pmap()的.f是命名函数,且有三个参数(),正好与三个同名元素(params$n,params$min,params$max)一样,则会自动匹配。
7. reduce()
参考:
1.https://bookdown.org/wangminjie/R4DS/tidyverse-purrr.html