本文总结Pandas中常用的统计学函数。
1. 常用函数
常用的统计学函数如下:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
在 DataFrame 中,使用聚合类方法时需要指定轴(axis)参数。
行:默认使用 axis=0 或者使用 “index”;
列:默认使用 axis=1 或者使用 “columns”。
如图所示: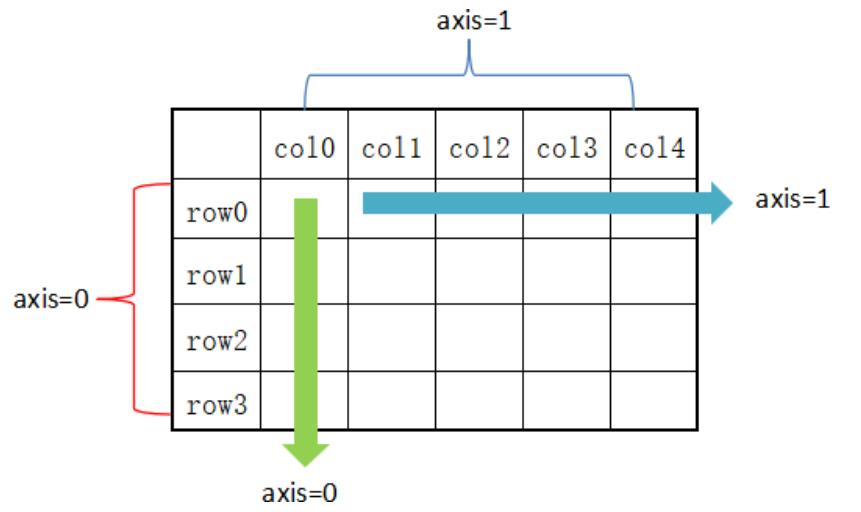
2. sum求和
创建DataFrame对象。
1 | > data = {'col1':pd.Series([1,2,3,4],index=['a','b','c']), |
默认情况下,sum()函数使用axis=0,按垂直方向进行计算。
对于字符串数据,不会得到异常,将字符串进行连接。
1 | > dd.sum() |
3. mean()求均值
1 | > dd.mean() |
4. std()求标准差
标准差:反应数据的离散程度。
1 | > dd.std() |
5. 数据汇总描述
describe()函数输出:均值、标准差、四分位值IQR等一系列信息。
1 | > dd.describe() |
include能够筛选字符列或者数字列的摘要信息。include 相关参数值说明如下:
object: 表示对字符列进行统计信息描述;
number:表示对数字列进行统计信息描述;
all:汇总所有列的统计信息。
1 | > dd.describe(include=['object']) |